
Diagnostic médical : les médecins battus à plate couture par ChatGPT, révèle une étude scientifique récente ; elle montre également que les médecins ne savent pas exploiter l’IA quand elle est mise à leur service
Les médecins voués à être remplacés par l’intelligence artificielle (IA) et ses robots conversationnels (« chatbots ») ? Sur leur compétence essentielle, le diagnostic, une étude clinique originale donne de résultats sans appel malgré la petite taille de l’échantillon : ChatGPT s’est révélé bien plus fiable que les médecins humains sur les rapports de cas médicaux présentés au professionnel et à la machine d’Open AI. Inquiétant aussi : les médecins ne s’en sortent pas mieux quand l’outil d’IA est mis à leur service.
Note introductive de la Rédaction : Afin de ne pas en perdre une miette et à des fins éducatives sur la méthodologie de la recherche clinique, et pour ceux qui ont le goût du détail et de la littérature scientifique, nous vous proposons en exclusivité la traduction française complète (hors références) de l’article scientifique (en anglais), résumé inclus, paru récemment dans la revue médicale JAMA Netw Open. Ces résultats font réfléchir sur le récent état des lieux mené par la Haute autorité de santé (HAS) concernant les erreurs de diagnostic des médecins français. Les auteurs de l’étude e concluent-ils que l’iA doit être incluse dans la pratique diagnostique pour les orienter ? Même pas, car, à la surprise de beaucoup, elle ne montre aucun performance diagnostique améliorée pour les médecins aidés par ChatGPT. Dans ces conditions, faut-il envisager un futur ou les médecins seront tout au plus les assistants des IA médicales ? La question est sérieuse.
Influence d’un grand modèle de langage sur le raisonnement diagnostique – Essai clinique randomisé (titre original : « Large Language Model Influence on Diagnostic ReasoningA Randomized Clinical Trial«
Auteurs :
Ethan Goh, MBBS, MS (Stanford University); Robert Gallo, MD (VA Palo Alto Health Care System) ; Jason Hom, MD (Stanford University School of Medicine); et al
Points clés
Question : L’utilisation d’un modèle de langage étendu (LLM) améliore-t-elle la performance du raisonnement diagnostique chez les médecins généralistes, de médecine interne ou de médecine d’urgence par rapport aux ressources conventionnelles ?
Résultats : Dans un essai clinique randomisé incluant 50 médecins, l’utilisation d’un LLM n’a pas amélioré de manière significative la performance du raisonnement diagnostique par rapport à la disponibilité de ressources conventionnelles.
Signification : Dans cette étude, l’utilisation d’un LLM n’a pas nécessairement amélioré le raisonnement diagnostique des médecins au-delà des ressources conventionnelles ; un développement supplémentaire est nécessaire pour intégrer efficacement les LLM dans la pratique clinique.
Résumé
Importance : Les grands modèles de langage (Large Language Models, LLMs) se sont révélés prometteurs dans leurs performances sur les examens de raisonnement médical à choix multiples et à questions ouvertes, mais on ne sait toujours pas si l’utilisation de ces outils améliore le raisonnement diagnostique des médecins.
Conception, cadre et participants : Un essai clinique randomisé en simple aveugle a été mené du 29 novembre au 29 décembre 2023. Des médecins formés en médecine générale, médecine interne ou médecine d’urgence ont été recrutés par vidéoconférence à distance et en personne dans plusieurs établissements médicaux universitaires.
Objectif : Évaluer l’effet d’un LLM sur le raisonnement diagnostique des médecins par comparaison avec les ressources conventionnelles.
Intervention : Les participants ont été randomisés [répartis au hasard, NDLR] pour accéder soit au LLM en plus des ressources diagnostiques conventionnelles, soit aux ressources conventionnelles uniquement, en fonction de leur stade de carrière. Les participants disposaient de 60 minutes pour examiner jusqu’à 6 vignettes cliniques.
Résultats et mesures principaux : Le résultat principal était la performance sur une grille standardisée de performance diagnostique basée sur la précision du diagnostic différentiel, la pertinence des facteurs de soutien et d’opposition, et les étapes suivantes de l’évaluation diagnostique, validées et l’objet d’un score par un consensus d’experts en aveugle. Les résultats secondaires comprenaient le temps passé par cas (en secondes) et la précision du diagnostic final. Toutes les analyses ont suivi le principe de l’intention de traiter. Une analyse exploratoire secondaire a évalué la performance autonome du LLM en comparant les résultats primaires entre le groupe LLM seul et le groupe de ressources conventionnelles.
Résultats : Cinquante médecins (26 titulaires, 24 résidents ; années médianes de pratique, 3 [IQR (écart intercartile, NDLR), 2-8]) ont participé virtuellement ainsi qu’à un site en personne. Le score médian de raisonnement diagnostique par cas était de 76 % (IQR, 66%-87%) pour le groupe LLM et de 74 % (IQR, 63 %-84 %) pour le groupe ressources conventionnelles uniquement, avec une différence ajustée de 2 points de pourcentage (IC à 95 %, -4 à 8 points de pourcentage ; P = 0,60). Le temps médian passé par cas pour le groupe LLM était de 519 (IQR, 371-668) secondes, comparé à 565 (IQR, 456-788) secondes pour le groupe des ressources conventionnelles, avec une différence de temps de -82 (IC à 95 %, -195 à 31 ; P = 0,20) secondes. Le LLM seul a obtenu 16 points de pourcentage (IC à 95 %, 2-30 points de pourcentage ; P = 0,03) de plus que le groupe des ressources conventionnelles.
Conclusions et pertinence : Dans cet essai, la mise à disposition d’un LLM aux médecins en tant qu’aide au diagnostic n’a pas amélioré de manière significative le raisonnement clinique par rapport aux ressources conventionnelles. Le LLM seul a démontré une performance supérieure à celle des deux groupes de médecins, ce qui indique la nécessité de développer la technologie et la main-d’œuvre pour réaliser le potentiel de la collaboration entre les médecins et l’intelligence artificielle dans la pratique clinique.
INTRODUCTION
Les erreurs de diagnostic sont fréquentes, contribuent à causer un préjudice important aux patients et résultent d’une combinaison de facteurs cognitifs et systémiques. Les interventions efficaces visant à améliorer la performance diagnostique et à réduire les erreurs diagnostiques nécessitent de se concentrer à la fois sur les facteurs systémiques et les facteurs cognitifs, souvent appelés raisonnement clinique. Les stratégies qui ont été avancées pour améliorer le raisonnement clinique comprennent une variété de pratiques éducatives, réflexives et d’équipe, ainsi que des outils d’aide à la décision clinique. L’impact de ces interventions a été limité ; en outre les méthodes les plus utiles telles que la pratique réflexive sont difficiles à intégrer à grande échelle d’un point de vue clinique. Les technologies d’intelligence artificielle (IA) sont depuis longtemps considérées comme des outils prometteurs pour aider les médecins à raisonner en matière de diagnostic.
Les grands modèles de langage (LLM), qui sont des systèmes d’apprentissage machine qui produisent des réponses semblables à celles de l’homme à partir du langage écrit, ont démontré leur capacité à résoudre des cas complexes, à faire preuve d’un raisonnement clinique semblable à celui de l’homme, à recueillir les antécédents des patients et à faire preuve d’une communication empathique. En raison de leur nature généralisable, les LLM sont activement intégrés dans de nombreux environnements de soins médicaux. Malgré les performances impressionnantes de ces technologies émergentes dans les tâches d’étalonnage, les intégrations actuelles des LLM nécessitent la participation humaine, le LLM augmentant plutôt que remplaçant l’expertise et la supervision humaines. Pour comprendre les implications du déploiement de ces systèmes dans les soins aux patients avec une formation et une intégration limitées de la main-d’œuvre, il faut des études sur les utilisateurs humains et informatiques avec des mesures plus riches du raisonnement diagnostique.
Nous avons réalisé un essai clinique randomisé pour comparer la performance du raisonnement diagnostique des médecins utilisant un agent conversationnel ( chatbot) du commerce LLM AI (ChatGPT Plus [GPT-4] ; OpenAI) par rapport aux ressources diagnostiques conventionnelles (par ex. UpToDate, Google). De nombreuses études sur les performances diagnostiques n’évaluent que des mesures superficielles de la précision sans prêter attention à la qualité du processus diagnostique utilisé pour parvenir à ce diagnostic. Pour mieux évaluer la façon dont les nouveaux outils affectent le raisonnement des médecins, nous avons adapté la réflexion structurée – une mesure des facteurs contribuant à une décision diagnostique – comme un nouvel outil d’évaluation du processus diagnostique.
MÉTHODES
Cette étude a été examinée et jugée exempte d’approbation par les comités d’examen institutionnels de l’université de Stanford, du centre médical Beth Israel Deaconess et de l’université de Virginie. Le consentement éclairé a été obtenu avant l’inclusion et la randomisation. Les participants résidents se sont vus offrir 100 dollars et les participants titulaires se sont vus offrir jusqu’à 200 dollars pour participer l’étude. Cette étude suit les directives CONSORT (Consolidated Standards of Reporting Trials) pour les essais cliniques randomisés. Le protocole de l’étude est disponible dans le supplément 1.
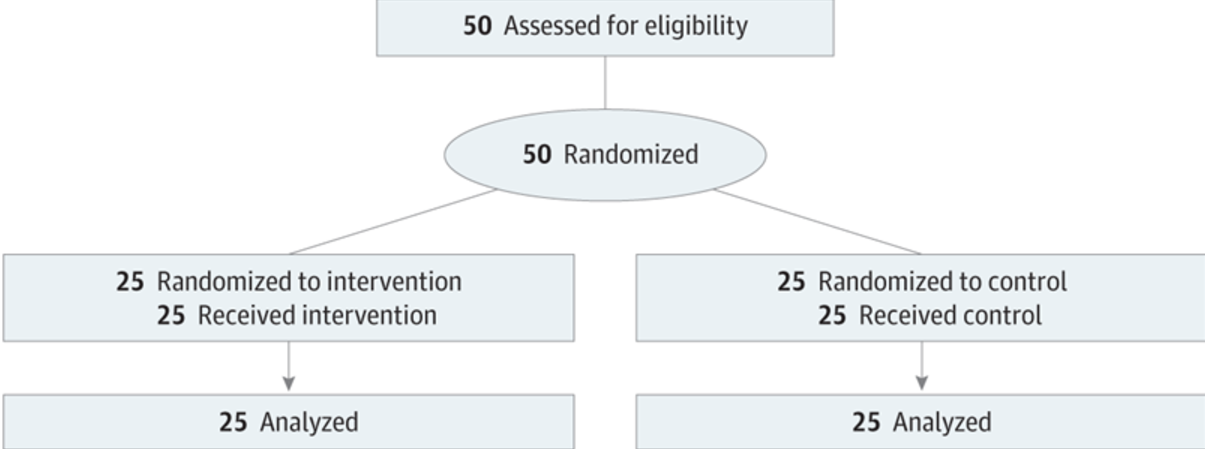
Nous avons recruté des médecins titulaires et résidents formés dans une spécialité médicale générale (médecine interne, médecine familiale ou médecine d’urgence) par le biais de listes d’adresses électroniques à l’université de Stanford, au Beth Israel Deaconess Medical Center et à l’université de Virginie. De petits groupes de participants ont été supervisés par des coordinateurs de l’étude, soit à distance, soit dans un laboratoire informatique en personne. Les sessions ont duré une heure. Le flux des participants est décrit dans cette figure :
Une itération visuelle est présentée dans cette figure :
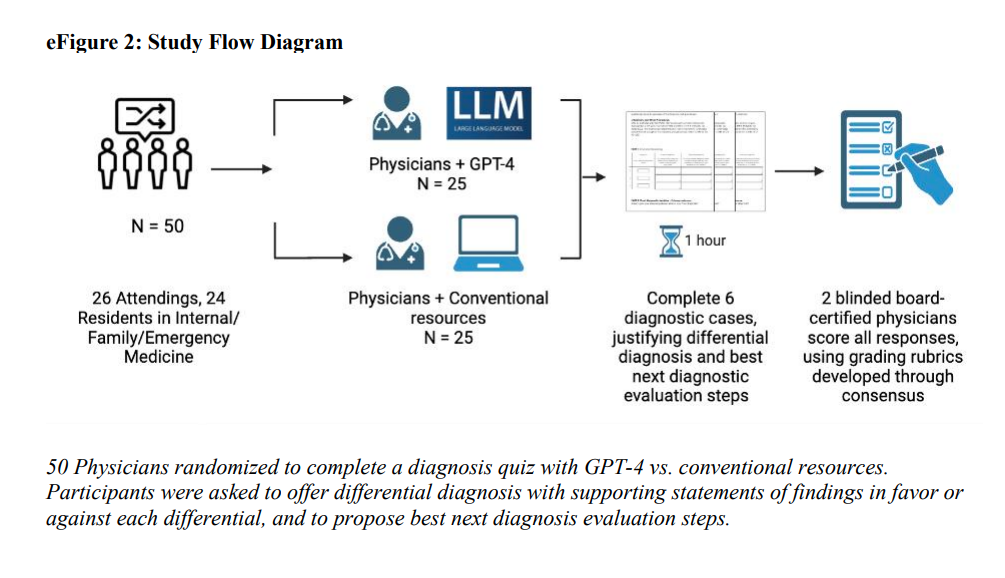
Vignettes cliniques
Les vignettes cliniques ont été adaptées à partir d’une étude historique qui a établi la norme pour l’évaluation des systèmes de diagnostic informatisés. Tous les cas de cette étude étaient basés sur des patients réels et incluaient des informations disponibles lors de l’évaluation diagnostique initiale, telles que les antécédents, l’examen clinique et les résultats des analyses de laboratoire. Les cas n’ont jamais été rendus publics afin de protéger la validité du matériel de test pour une utilisation future, et sont donc exclus des données de formation du LLM.
Nous avons utilisé la technique du groupe nominal pour sélectionner un échantillon de cas ; quatre médecins auteurs (E.G., J.A.C., A.P.J.O. et J.H.C.) se sont réunis pour se mettre d’accord sur les directives de sélection des cas, y compris la préférence pour un large éventail de contextes pathologiques, en évitant les cas simplistes avec des diagnostics plausibles limités, et en excluant les cas excessivement rares.24 Chaque membre a examiné indépendamment au moins 50 des 105 cas disponibles pour identifier un minimum de 10 cas qui satisfont aux directives de sélection. Après les évaluations individuelles, le groupe s’est réuni à nouveau pour parvenir à un consensus sur une liste de cas à examiner en priorité. Lors des tests pilotes, les participants ont complété un maximum de 6 cas en 1 heure, ce qui nous a permis de sélectionner 6 cas finaux pour cette étude. Les cas ont été édités pour moderniser les conventions de rapport des données de laboratoire et pour remplacer les phrases pathognomoniques (par exemple, livedo reticularis) par des descriptions générales.
La précision du diagnostic différentiel est un critère d’évaluation courant, mais limité, dans les études diagnostiques sur l’aide à la décision clinique. Bien que nous ayons évalué la précision globale du diagnostic différentiel en tant que résultat secondaire, à l’instar d’études antérieures, les phénomènes complexes des interactions entre l’homme et l’ordinateur justifient des évaluations plus riches des compétences en matière de raisonnement diagnostique. Nous avons donc choisi de développer une évaluation à partir de la littérature sur le raisonnement clinique : la réflexion structurée.
La réflexion structurée vise à améliorer le processus par lequel les médecins considèrent les diagnostics raisonnables et les caractéristiques cliniques qui soutiennent ou s’opposent à leurs diagnostics, de la même manière que les médecins peuvent expliquer leur raisonnement dans la composante d’évaluation et de planification des notes cliniques. Nous avons adapté une grille de réflexion structurée avec des participants fournissant des réponses en texte libre sur leurs 3 principaux diagnostics différentiels, les facteurs dans le cas qui favorisent ou s’opposent à chacun de leurs 3 diagnostics, leur diagnostic final le plus probable, et jusqu’à 3 étapes suivantes (par ex., tests diagnostiques) qu’ils utiliseraient pour poursuivre l’évaluation du patient.
Évaluation des performances
Nous nous sommes appuyés sur des études antérieures portant sur la réflexion structurée en évaluant la grille elle-même, et non pas seulement l’exactitude du diagnostic final. Pour chaque cas, nous avons attribué jusqu’à 1 point pour chaque diagnostic plausible. Les résultats étayant chaque diagnostic et les résultats s’opposant au diagnostic ont également été notés en fonction de leur exactitude, avec 0 point pour les réponses incorrectes ou absentes, 1 point pour les réponses partiellement correctes et 2 points pour les réponses entièrement correctes. Le diagnostic final a été noté sur 2 points pour le diagnostic le plus correct et sur 1 point pour un diagnostic plausible ou un diagnostic correct qui n’était pas assez précis par rapport au diagnostic final le plus correct. Les participants devaient ensuite décrire jusqu’à trois étapes suivantes pour poursuivre l’évaluation du patient, 0 point étant attribué pour une réponse incorrecte, 1 point pour une réponse partiellement correcte et 2 points pour une réponse totalement correcte. Si les diagnostics différentiels incorrects n’ont pas été récompensés, le raisonnement approprié basé sur ces diagnostics n’a pas été pénalisé. Les évaluateurs n’ont pas été informés de l’affectation des groupes de participants.
Conception de l’étude
Nous avons utilisé un modèle d’étude randomisé en simple aveugle avec randomisation stratifiée. Les participants ont été répartis au hasard entre l’utilisation de l’interface LLM (groupe d’intervention) et les ressources conventionnelles (groupe de contrôle). Ils ont eu accès à des comptes d’étude pour le LLM et les transcriptions de leur utilisation ont été sauvegardées. Les deux groupes ont reçu l’instruction d’accéder à toutes les ressources conventionnelles qu’ils utilisent normalement pour les soins cliniques, mais le groupe de contrôle a reçu l’instruction explicite de ne pas utiliser les LLM. Les participants disposaient d’une heure pour compléter autant de cas diagnostiques que possible, avec pour instruction de donner la priorité à la qualité de leurs réponses plutôt qu’à la complétion de tous les cas.
L’étude a été réalisée à l’aide d’un outil d’enquête (Qualtrics), les cas étant présentés dans un ordre aléatoire pour chaque participant. Dans une analyse secondaire, nous avons inclus un groupe témoin utilisant uniquement le LLM pour répondre aux cas. En utilisant les principes établis de la conception des messages-guides, nous avons développé de manière itérative un message-guide 0-shot ; le même langage a été utilisé avec les questions de la vignette clinique pour chaque cas.27 Le médecin chercheur qui a entré les messages-guides dans le modèle n’a pas modifié les réponses du modèle. Ces invites ont été exécutées trois fois au cours de sessions distinctes, et les résultats de chaque exécution ont été inclus pour une évaluation en aveugle avec les résultats humains avant la levée de l’aveugle ou l’analyse des données.
Validation de l’outil d’évaluation
Pour établir la validité, nous avons recueilli deux séries de données pilotes auprès de 13 participants qui n’ont pas été inclus dans l’étude finale. Au total, 65 cas ont été menés à bien, sur la base d’un échantillonnage de plusieurs vignettes de cas, dont les 6 utilisées dans l’étude finale. Les trois évaluateurs principaux (J.H, A.P.J.O. et A.R.), tous des médecins certifiés ayant de l’expérience dans l’évaluation du raisonnement clinique au niveau médical post-universitaire, ont noté ces cas indépendamment afin d’évaluer la cohérence. Sur la base des commentaires itératifs des correcteurs et des participants pilotes, ainsi que de la concordance des correcteurs, les vignettes des cas étudiés ont été sélectionnées et les rubriques ont été affinées avant que les données ne soient collectées pour l’étude finale. Après la collecte des données, chaque cas a été noté indépendamment par deux évaluateurs qui ne connaissaient pas le groupe de traitement assigné. Le désaccord entre les évaluateurs a été prédéfini comme une différence de plus de 10 % du score final. En cas de désaccord, les évaluateurs se sont réunis pour discuter des différences entre leurs évaluations et rechercher un consensus. Nous avons conçu la notation de manière à reconnaître intentionnellement l’ambiguïté des processus de diagnostic, en autorisant de multiples variations des réponses correctes déterminées par le consensus des évaluateurs. La notation du diagnostic final a été évaluée par deux évaluateurs afin d’obtenir un accord sur le résultat secondaire de la précision du diagnostic. Nous avons calculé une valeur pondérée de Cohen κ pour montrer la concordance de la notation et une valeur de Cronbach α pour déterminer la fiabilité interne de cette mesure.
Résultats de l’étude
Notre résultat principal était le score final en pourcentage pour toutes les composantes de l’outil de réflexion structuré. Les résultats secondaires étaient le temps passé par cas (en secondes) et la précision du diagnostic final. Le diagnostic final a été traité comme un résultat ordinal avec 3 groupes (incorrect, partiellement correct et le plus correct). Étant donné que la différence entre la réponse la plus correcte et les réponses partiellement correctes peut ne pas être cliniquement significative, nous avons également analysé le résultat comme un résultat binaire (incorrect comparé à au moins partiellement correct).
Analyse statistique
La taille de l’échantillon cible de 50 participants a été prédéfinie sur la base d’une analyse de puissance utilisant deux ensembles de données de validation, notés avant l’inscription à l’étude. En utilisant le logiciel PASS 2023, version 23.0.2 (NCSS LLC), notre analyse de puissance a montré une puissance de plus de 80 % pour détecter une différence de score de 8 % avec 200 à 250 cas complétés (4 à 5 cas par participant) avec une valeur α bilatérale de 0,05. Nous avons utilisé un modèle à effets mixtes adapté aux plans randomisés en grappes, avec un coefficient de corrélation intraclasse allant de 0,05 à 0,15 et un écart-type de 16,2 %.
Toutes les analyses ont respecté le principe de l’intention de traiter et ont été effectuées au niveau des cas, regroupés par participant. Des modèles linéaires à effets mixtes ont été appliqués pour évaluer la différence entre le résultat primaire de la performance diagnostique et le résultat secondaire du temps passé par cas traité, les hypothèses de normalité ayant été vérifiées. Des modèles à effets mixtes ordinaux et logistiques ont été utilisés pour comparer d’autres résultats secondaires, y compris la précision du diagnostic final ordinal et binaire. Un effet aléatoire pour le participant a été inclus dans les modèles pour tenir compte de la corrélation potentielle entre les cas d’un même participant. En outre, un effet aléatoire pour les cas a été inclus pour tenir compte de toute variabilité potentielle de la difficulté entre les cas. L’erreur de type I (α) à l’échelle de la famille a été contrôlée à 0,05 pour le résultat principal de la performance diagnostique considérée comme une variable continue. L’analyse des résultats secondaires a été exploratoire sans ajustement pour les comparaisons multiples. Une analyse de sensibilité planifiée à l’avance a évalué l’effet de l’inclusion de cas incomplets sur le résultat primaire. Des analyses de sous-groupes ont été réalisées en fonction du statut de formation et de l’expérience avec le produit LLM utilisé. Dans une analyse secondaire, les cas complétés par le LLM seul ont été traités comme un troisième groupe, avec des cas regroupés dans une structure imbriquée de 3 tentatives sous la responsabilité d’un seul participant. Ces cas ont été comparés à ceux de participants réels, chaque cas étant considéré comme une tentative unique sous la direction d’un participant unique utilisant une structure imbriquée similaire. Toutes les analyses statistiques ont été réalisées à l’aide de R, version 4.3.2 (R Foundation for Statistical Computing).
Résultats
Cinquante médecins agréés aux États-Unis ont été recrutés et ont participé (26 titulaires, 24 résidents) du 29 novembre au 29 décembre 2023 ; parmi eux, 39 (78 %) ont participé à des rencontres virtuelles et 11 (22 %) à des rencontres en personne. Le nombre médian d’années de pratique était de 3 (IQR, 2-8).
Résultat principal : performances en termes de diagnostic
Au total, 244 cas ont été réalisés par tous les participants (125 cas dans le groupe LLM, 119 cas dans le groupe de contrôle). Le nombre médian de cas complétés par participant était de 5 (IQR, 4-6). L’analyse des transcriptions a montré que 100 % (22 sur 22) des médecins randomisés pour utiliser le LLM l’ont fait ; 3 transcriptions ont été perdues en raison de problèmes techniques et n’ont pas été incluses. Le score médian par cas était de 76 % (IQR, 66 %-87 %) pour le groupe LLM et de 74 % (IQR, 63%-84%) pour le groupe de contrôle. Le modèle à effets mixtes a montré une différence de 2 points de pourcentage (IC à 95 %, -4 à 8 points de pourcentage ; P = 0.60) entre le groupe LLM et le groupe de contrôle. Une analyse de sensibilité incluant tous les cas, complets et incomplets, a montré un résultat similaire avec une différence de 2 points de pourcentage (IC à 95 %, -4 à 8 points de pourcentage ; P = 0.50) entre le groupe LLM et le groupe de contrôle.
Résultats secondaires
Le temps médian passé par cas était de 519 (IQR, 371-668) secondes pour le groupe LLM et de 565 (IQR, 456-788) secondes pour le groupe de contrôle. Le modèle linéaire à effets mixtes a abouti à une différence ajustée de -82 secondes (IC à 95 %, -195 à 31 secondes ; P = 0.20).
L’exactitude du diagnostic final utilisant l’échelle ordinale a montré que le groupe d’intervention LLM avait 1,4 fois plus de chances (IC à 95 %, 0,7-2,8 ; P = 0,39) d’obtenir un diagnostic correct que le groupe de contrôle. Lors de l’évaluation de la précision des diagnostics finaux, le fait de les traiter comme des variables binaires (correctes ou incorrectes) n’a pas modifié qualitativement les résultats (rapport de cotes, 1,9 ; IC à 95 %, 0,9-4,0 ; P = 0,10).
Les analyses par sous-groupe étaient qualitativement similaires aux analyses pour l’ensemble de la cohorte.
LLM seul
Dans les 3 essais du LLM seul, le score médian par cas était de 92 % (IQR, 82 % – 97 %). La comparaison du LLM seul avec le groupe de contrôle a révélé une différence de score absolu de 16 points de pourcentage (IC à 95 %, 2 à 30 points de pourcentage ; P = 0.03) en faveur du LLM seul.
Validation de l’outil d’évaluation
La valeur pondérée de Cohen κ entre les trois évaluateurs était de 0,66, ce qui indique un accord substantiel dans la fourchette attendue pour les études de performance diagnostique.30 La valeur globale de Cronbach α était de 0,64. Les variances des sections individuelles de la grille de réflexion structurée sont présentées dans le tableau 5 du supplément 2. Après avoir supprimé le diagnostic final, qui présentait la variance la plus élevée, la valeur α de Cronbach était de 0,67.
DISCUSSION
Cet essai clinique randomisé a montré que l’utilisation par les médecins d’un agent conversationnel (chatbot) LLM disponible dans le commerce n’a pas amélioré le raisonnement diagnostique sur des cas cliniques difficiles, bien que le LLM seul ait obtenu des résultats nettement supérieurs à ceux des médecins participants. Les résultats étaient similaires dans les sous-groupes de différents niveaux de formation et d’expérience avec le chatbot. Ces résultats suggèrent que l’accès seul aux LLM n’améliorera pas le raisonnement diagnostique global des médecins dans la pratique. Ces résultats sont particulièrement pertinents à l’heure où de nombreux systèmes de santé proposent des chatbots conformes à la loi sur la portabilité et la responsabilité de l’assurance maladie (Health Insurance Portability and Accountability Act [spécifique aux États-Unis, NDLR]) que les médecins peuvent utiliser en milieu clinique, souvent sans aucune formation, voire avec une formation minimale sur l’utilisation de ces outils.
Nos données n’ont pas confirmé de différences dans le temps consacré à la résolution des cas. Compte tenu de la grande variabilité observée dans le temps consacré à la résolution des cas, il serait nécessaire de mener de futures études avec des échantillons beaucoup plus importants pour évaluer si les médecins ayant l’expérience de l’utilisation des LLM consacrent moins de temps au raisonnement diagnostique.
Un résultat secondaire inattendu est que le LLM seul a été nettement plus performant que les deux groupes d’humains, à l’instar d’étude récente avec une technologie LLM différente. Cela peut s’expliquer par la sensibilité de la sortie LLM à la formulation de l’invite. Il existe de nombreux cadres pour l’invite des LLM et un consensus émergent sur les stratégies d’invite, dont beaucoup se concentrent sur la fourniture de détails sur la tâche, le contexte et les instructions ; notre invite a été développée de manière itérative en utilisant ces cadres. La formation des cliniciens aux meilleures pratiques d’incitation peut améliorer la performance des médecins avec les LLM. Par ailleurs, les organisations pourraient investir dans des messages-guides prédéfinis pour l’aide à la décision diagnostique, intégrés dans les flux de travail cliniques et la documentation, ce qui permettrait une synergie entre les outils et les cliniciens. Des études antérieures sur les systèmes d’IA montrent des effets disparates en fonction de l’élément du processus de diagnostic dans lequel ils sont utilisés. Étant donné la nature conversationnelle des agents conversationnels (chatbots), des changements dans la manière dont le LLM interagit avec les humains, par ex., en signalant spécifiquement les caractéristiques qui ne correspondent pas au diagnostic différentiel, pourraient améliorer le diagnostic et la performance de réflexion.35,36 De manière plus générale, nous voyons une opportunité dans l’examen délibéré et la refonte de l’éducation médicale et des cadres de pratique qui s’adaptent aux technologies émergentes perturbatrices et permettent la meilleure utilisation des ressources informatiques et humaines pour fournir des soins médicaux optimaux.
Les résultats de cette étude ne doivent pas être interprétés comme indiquant que les LLM devraient être utilisés pour le diagnostic de manière autonome sans la supervision d’un médecin. Les vignettes de cas cliniques ont été classées et résumées par des cliniciens humains, une approche pragmatique et courante pour isoler le processus de raisonnement diagnostique, mais cela ne tient pas compte des compétences dans de nombreux autres domaines importants pour le raisonnement clinique, y compris l’entretien avec le patient et la collecte de données. En outre, cette étude était hors contexte, et la compréhension de l’environnement clinique par les cliniciens est fondamentale pour une prise de décision de haute qualité. Bien que les premières études montrent que les LLM peuvent collecter et résumer efficacement les informations sur les patients, ces capacités doivent être étudiées de manière plus approfondie. En outre, l’amélioration de la notation des rubriques représente ici un signal important du raisonnement clinique, mais des essais cliniques plus larges sont nécessaires pour évaluer les différences significatives dans l’impact clinique en aval.
Cette étude a développé une mesure basée sur la réflexion structurée, inspirée par la recherche sur la cognition des médecins. La notation de l’outil de réflexion structurée adapté en tant que résultat principal représente une nouvelle contribution de cette étude pour offrir un cadre d’évaluation plus riche des compétences de raisonnement diagnostique. Cet outil d’évaluation a démontré une concordance substantielle entre les évaluateurs et une fiabilité interne similaire ou supérieure à d’autres mesures utilisées dans l’évaluation du raisonnement.39-42 Cela fait progresser le domaine au-delà des premières recherches sur le LLM, qui se sont concentrées sur des repères ayant une utilité clinique limitée, tels que les banques de questions à choix multiples utilisées pour l’obtention de la licence médicale ou les vignettes de cas curatées de maladies rarement vues en pratique clinique, telles que les conférences de cas cliniques pathologiques. Bien qu’elles présentent des avantages évidents en termes de facilité de mesure, ces tâches ne correspondent pas au raisonnement clinique dans la pratique. Au fur et à mesure que la recherche en IA progresse et se rapproche de l’intégration clinique, il deviendra encore plus important de mesurer de manière fiable la performance diagnostique en utilisant les méthodes d’évaluation et métriques les plus réalistes et les plus pertinentes d’un point de vue clinique.
Limites
Cet essai a ses limites. Nous avons axé notre enquête sur un seul LLM, étant donné sa disponibilité commerciale et son intégration dans la pratique clinique. De multiples systèmes LLM alternatifs émergent rapidement, bien que celui étudié reste actuellement parmi les outils les plus performants pour les applications étudiées. Les participants ont eu accès au agents conversationnels (chatbots) sans formation explicite aux techniques d’ingénierie rapide qui auraient pu améliorer la qualité de leurs interactions avec le système ; cependant, ceci reste conforme aux intégrations actuelles et nécessite donc cette évaluation représentative.15,17-19 En outre, même si tous les médecins du groupe LLM ont au moins essayé d’utiliser le système sur la base des journaux de chat, ils n’ont pas été forcés d’utiliser le système d’une manière cohérente. Il s’agissait d’une conception délibérée visant à mieux refléter une évaluation de l’efficacité dans le cadre de la pratique clinique.
Aucun échantillon de vignettes cliniques ne peut couvrir de manière exhaustive la variété des cas dans le domaine de la médecine. Notre étude a porté sur 6 cas qui pouvaient être traités en une seule session d’étude tout en restant comparables aux pratiques courantes dans les examens cliniques structurés nationaux d’autorisation et d’objectifs, qui consistent à utiliser un échantillon restreint mais large de cas cliniques.6,46-49 Il ne s’agit pas d’évaluer de manière exhaustive les connaissances d’un participant, mais plutôt d’évaluer son raisonnement clinique général à travers un ensemble de cas. Pour optimiser l’étendue de la couverture, nous avons délibérément choisi des cas qui représentent un échantillon large et pertinent de disciplines et un éventail de problèmes cliniques.
CONCLUSION
La disponibilité d’un LLM en tant qu’aide au diagnostic n’a pas amélioré la performance des médecins par rapport aux ressources conventionnelles dans un essai clinique randomisé sur le raisonnement diagnostique. Le LLM seul a surpassé les performances des médecins même lorsque le LLM était à leur disposition, ce qui indique qu’un développement plus poussé des interactions homme-machine est nécessaire pour réaliser le potentiel de l’IA dans les systèmes d’aide à la décision clinique.
Note de la Rédaction : pour la commodité de lecture, les références bibiographiques et internes ont été retirées ; elles sont disponibles dans l’article original.
Science infuse est un service de presse en ligne agréé (n° 0324 x 94873) piloté par Citizen4Science, association à but non lucratif d’information et de médiation scientifique doté d’une Rédaction avec journalistes professionnels. Nous défendons farouchement notre indépendance. Nous existons grâce à vous, lecteurs. Pour nous soutenir, faites un don ponctuel ou mensuel.

